새소식
반응형
평소에 Convolution Neural Network (CNN)을 자주 들여다봅니다. 그러다보니 궁금증은 한없이 많고, 저처럼 CNN을 연구, 공부하면서 궁금해하실 분도 많을 것 같아 몇 자 끄적여봅니다.
어디까지나 광활한 정보의 바다에서 정답인지 아닐지 모를 정보를 바탕으로 정립을 해본 것이니, 내용이 틀리다면 언제든 말씀해주셔도 좋습니다.
아래 이미지에서, 초록색의 이미지에 노란색의 3X3 필터를 왼쪽위부터 오른쪽아래까지 한칸씩 합성곱을 한다. 그러면 핑크색의 feature가 나옵니다.

여기까지는 이론입니다. 실제 합성곱 필터를 적용하여 feature를 시각화해보면,

이런 양상을 띄게 됩니다. CNN은 입력에 가까울수록 edge, 색깔 등 큰 특징을 보고 출력에 가까울수록 디테일한 부분을 봅니다. 이 그림으로는 어렴풋이 이해가 됩니다.
하지만,
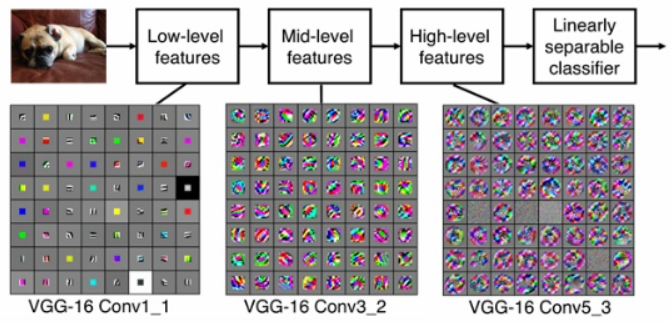
위의 예시에서는 도대체 뭘 보고 있는건지 도통 이해가 가지 않았습니다. 최근 이미지 분류의 네트워크들은 매우 깊기 때문에, 출력에 가까울수록 feature map은 더 작아지고, 도통 내가 만든 CNN이 뭔 특징을 보고 있는건지 설명을 하기가 힘들었습니다.
제가 실험적으로 판단했을 때는, 학습된 네트워크의 각 conv 레이어의 각 필터들은 맡고 있는 역할이 정해져 있었습니다. 예를 들어, 첫번쨰 convolution layer의 필터 수를 32개로 정의하고 학습을 하였을 때 피처맵을 뽑아보면 첫 번째 conv layer의 32개 필터 중 첫 번째 필터는 엣지만 보고 있고, 두 번째 필터는 배경의 질감만 파악하고 있고, 세 번째 필터는 object를 반전시켜 지켜보고 있고... 이런식으로 항상 각 필터는 자기가 맡은 역할을 정해놓고 이미지를 변화시켜서 보고 있었다는 것을 확인했습니다.
나름의 해답을 얻은 것은 이미 사전정보가 많은 연구자와 인공지능이 학습하는 방식이 다르고, 인간과 기계의 학습방식이 다르다는 것이었습니다. 이 간극을 줄인다면 기계가 학습하는 방식에 빙의(?)하여 최고의 성능을 가지는 모델을 만들 수 있을 것 같습니다.
물론 네트워크를 만드는 방식 또는 학습방식은 사람의 학습방식을 모방하여 만듭니다. 실제로 성능 또한 뛰어납니다. self-supervised learning, transfer learning 이런 방식은 다 사람의 학습방식을 모방하여 탄생하였습니다.
하지만 저의 경우 NASnet같은 AutoML로 만들어진 CNN들은 분석하기 쉽지 않았습니다. Imagenet에서 결과가 좋은건 알겠는데, 오분류 데이터들을 분석하는 과정에서 단순하고 직관적인 CNN보다 분석이 매우 힘들었습니다. 또한 Imagenet 데이터셋을 타겟으로 만들어진 CNN이라, 다른 도메인에서 잘 될지도 미지수였습니다.
32x32 또는 16x16 feature map까지는 인간의 영역으로 이해를 해보겠는데, 8x8이하의 feature map에서는 인간의 인지를 아득히(?) 넘어버린 추상화가 진행되어 모델을 분석하는 사람의 입장에서는 어려움이 있네요.!!
그래서 머신러닝은 실험적인게 크지 않나 생각합니다 ㅎㅎ 사람이 기계의 학습방식을 그대로 녹여내어 모델을 개선하긴 힘드니깐요!
| mmclassification config 작성법 (0) | 2023.04.16 |
|---|---|
| VGGnet의 구조 + keras code (0) | 2021.08.23 |
| tf.keras로 CIFAR-10 데이터 학습하기 (0) | 2021.02.11 |
| CIFAR-10 데이터 분석하기 (0) | 2021.02.04 |
| K-fold cross validation (0) | 2019.11.09 |
소중한 공감 감사합니다!