개념 정리
완벽히 알진 못하여 틀린 부분이 있을 수 있습니다. 틀린 부분이 있다면 말씀 부탁드립니다.
모델 최적화 및 가속
- OPenVINO
- 인텔에서 제공하는 딥러닝 최적화 및 하드웨어 가속화 기능을 가진 툴킷
- Intel CPU 아키텍처에 모델을 최적화시켜 인퍼런스 타임을 pytorch 대비 10배 가량 향상시켜 주는 모델 최적화 방법, 누군가 실험해 본 벤치마크상 인퍼런스 타임이 1/10 정도로 감소, 모델 용량은 그대로임.
- Intel CPU 인퍼런스를 하는 환경이라면 OPenVINO
- TensorRT
- Nvidia GPU를 사용하는 연산을 보조하기 위한 기술, 딥러닝 모델 추론 속도를 향상시키는 모델 최적화 엔진
- Nvidia GPU에 모델을 최적화 시켜 인퍼런스 타임을 pytorch 대비 5~10배 향상 시키는 모델 최적화 방법, nvidia GPU를 사용하는 환경이라면 TensorRT
- Segmentation에서는 TRT FP32 → TRT FP16 quantization도 인퍼런스 타임이 1.5~2배 정도 향상하는 것으로 보임.
- ONNX
- Open Neural Network Exchange (ONNX)
- 다른 프레임워크에서 만들어진 모델을 호환해서 사용하도록 함
- 배치 사이즈가 작을 때(4이하) torch보다 2배 가량 빠르나, 배치사이즈가 커지면 torch 2.0과 별 차이 없음, torch 1버전도 마찬가지
- Microsoft의 ONNX runtime
- Intel의 nGraph
- Pytorch 2.0
- 1버전 때보다 배치 사이즈가 커질수록 전버전 대비 큰 성능 향상
- 그림1 참고
- NCNN
- mobile platform을 위해 neural network inference를 최적화하는 framework
- RKNN
- REX 보드에서 동작하기 위한 프레임워크
(REX 보드가 뭔지 잘..)
Post-Training Quantization (PTQ)
- 모델의 type 변환을 통해 딥러닝 추론속도를 높이는 방법
- Calibration dataset을 사용하여 FP32, INT8 레이어의 출력 분포를 계산하고, KL divergence가 가장 작은(정보의 손실이 가장 작은) 임계점을 선택하여 레이어를 변환하는 과정
- FP32 → FP16 : 모델 용량이 절반이 되나 인퍼런스 타임이 감소하지는 않음 (학습속도 향상 효과)
- FP32 → int8 : 모델 용량 1/4 정도로 감소, 인퍼런스 타임은 50~60% 가량 감소
💁실제 실험에서는 결과가 다를 수 있습니다
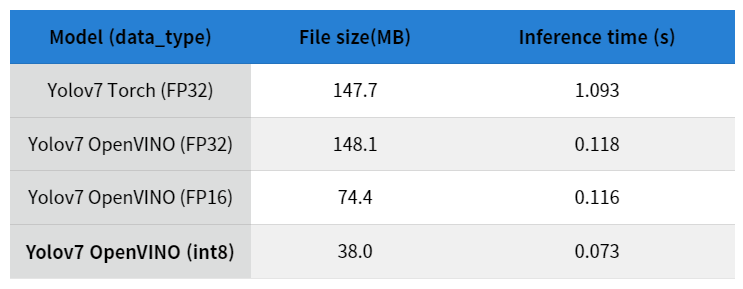 그림1. 누군가 실험해 본 모델 용량과 인퍼런스 타임 비교 https://da2so.tistory.com/65
그림1. 누군가 실험해 본 모델 용량과 인퍼런스 타임 비교 https://da2so.tistory.com/65
 그림2. https://www.nebuly.com/blog/pytorch-2-0-inference-performance
그림2. https://www.nebuly.com/blog/pytorch-2-0-inference-performance